
Die robots.txt - alles was Sie darüber wissen sollten
Was ist rein robots.txt?
Die robots.txt-Datei wird im Stammverzeichnis einer Webseite abgelegt und enthält Anweisungen zur Steuerung der sogenannten Suchmaschinen-Robots. Wird eine Webseite aufgerufen, sucht der Robot zunächst die Datei „robots.txt“ und liest diese aus. Der Inhalt dieser Datei teilt dem Crawler mit, welche Teile der Webseite für den Google-Index bestimmt sind. Mittels bestimmter Anweisungen können Verzeichnisse, einzelne Dokumente und gar einzelne Dateitypen explizit von der Indexierung ausgeschlossen werden.
Diese Datei hat sich im Laufe der Zeit zwar zu einem Standard entwickelt, ist jedoch nicht bindend. Suchmaschinen können den Anweisungen in der robots.txt folgen, sind dazu jedoch nicht verpflichtet.
Wo finden Sie Ihre robots.txt?
Ihre robots.txt muss exakt unter diesem Namen im Wurzelverzeichnis Ihrer Domain abgelegt werden. Die URL lautet demnach folgendermaßen: www.ihre-webseite.de/robots.txt
Sofern Sie Ihre Webseite in der Google Search Console (ehemals Webmaster Tools) angemeldet haben, kann die Datei unter „Crawling – Blockierte URLs“ eingesehen und getestet werden.
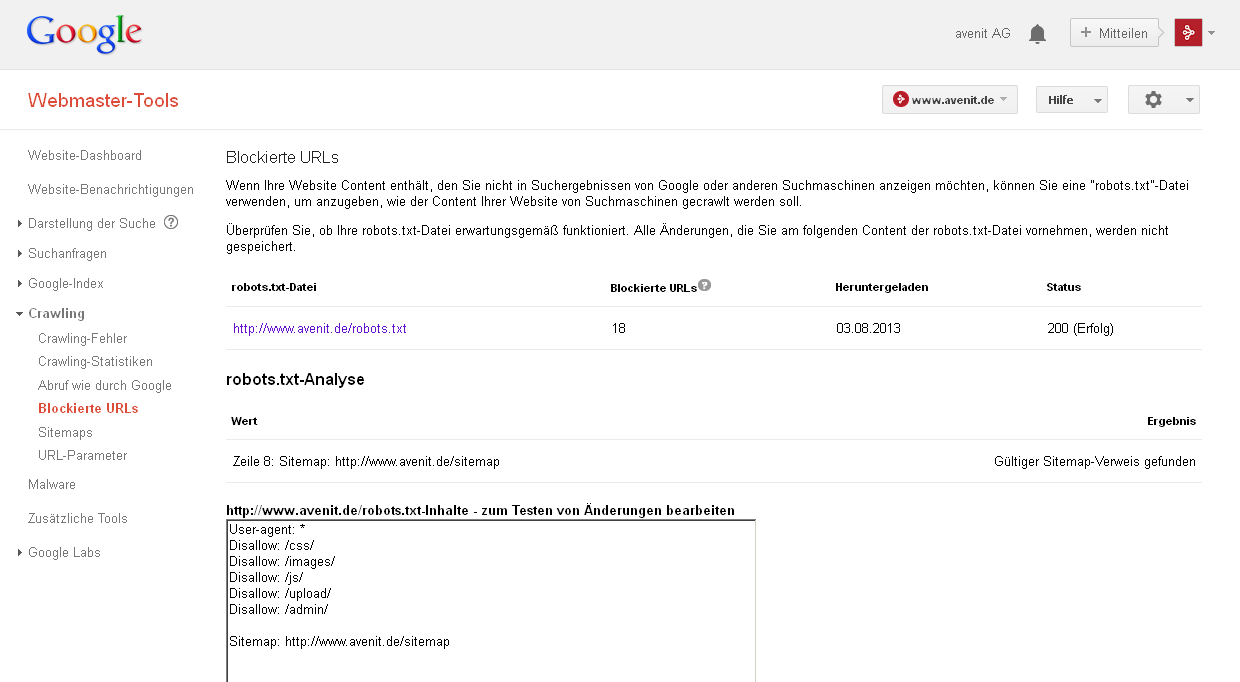
Wie wird eine robots.txt programmiert?
1. Kommentar
Ist die robots-Datei umfangreicher, können Kommentare mit einem vorangestellten Lattenkreuz gekennzeichnet werden.
# avenit erklärt die robots.txt
2. Robotansprache
Zu Beginn wird der entsprechende Crawler angesprochen. Verwenden Sie dafür den einleitenden Befehl „User-agent:“.
# avenit erklärt die robots.txt
User-agent: Googlebot
3. Ausschließen
Der Begriff „Disallow“ ermöglicht Ihnen die Definition von Ordnern und Verzeichnisse, welche nicht durchsucht werden dürfen.
# avenit erklärt die robots.txt
User-agent: Googlebot
Disallow: /admin/
Disallow: /upload/
4. Einschließen
Die robots.txt kennt auch das Kommando „Allow“. Dieser Befehl definiert Ordner und Verzeichnisse, welche durchsucht werden dürfen und ist damit eher umstritten. Die Crawler sind ohnehin nicht an die Einhaltung der robots.txt gebunden.
# avenit erklärt die robots.txt
User-agent: Googlebot
Disallow: /admin/
Disallow: /upload/
Allow: /includes/
5. PDF-Dateien
Wollen Sie z.B. alle PDF-Dateien auf Ihrer Seite vor der Aufnahme in den Index schützen verwenden Sie folgenden Befehl:
# avenit schützt PDF-Dateien
User-agent: *
Disallow: /*.pdf$
6. Google-Image
Nicht nur zu SEO-Zwecken ist es hilfreich über die Bildersuche Traffic zu generieren. Mit dem folgenden Begriff erlauben Sie dem Google-Robot explizit den Zugriff auf die Bilddateien des angegebenen Ordners.
# avenit erklärt Google-Image
User-agent: Google-Image
Allow: /wp-content/uploads/
7. Sitemap
Machen Sie die Crawler mit dem folgenden Kommando auf Ihre XML-Sitemap aufmerksam.
# avenit erklärt Sitemap
Sitemap: www.ihre-webseite.de/sitemap
Während und nach der Programmierung sollte eine korrekte Schreibweise der Befehle unbedingt beachtet werden. Leerzeichen und vor allem Schrägstriche müssen mit Bedacht gesetzt werden. Wird der Schrägstrich am Ende vergessen, ist das komplette Verzeichnis ein- oder ausgeschlossen. Im folgenden Beispiel geht der Crawler davon aus, dass alle Ordner, welche mit „includes“ beginnen, ausgeschlossen sind.

Fazit
Die Steuerdatei sollte Bestandteil jeder Webseite sein, sie dient nicht nur dem Schutz von Inhalten, sondern ist auch aus Gründen der Suchmaschinenoptimierung empfehlenswert: Ein Suchmaschinen-Robot crawlt pro Webseite nur eine bestimmte Anzahl an Seiten. Um sicherzustellen, dass dieses begrenzte Kontingent nicht durch unwichtige Dateien, wie beispielsweise CSS-Dateien, verbraucht wird, ist der Einsatz einer robots.txt notwendig. Auch die Punkte 6 und 7 (Einbeziehung der Bilder und der Sitemap) sind zu Optimierungszwecken sinnvoll. Eine Längenbegrenzung gibt es für die robots.txt nicht, eine überschaubare Gestaltung wird jedoch empfohlen.
Hinweis: Ein Ausschluss mit „Disallow“ bedeutet nicht zwingend, dass die Seite nicht in den Index der Suchmaschinen gelangt. Ist sie von einer externen Seite verlinkt, wird die URL gespeichert, ohne das der Bot sie je besucht hat. Um eine Seite komplett von dem Index auszuschließen, sollte im Quelltext mit dem noindex-Metatag gearbeitet werden („<meta content="noindex,follow" name="robots">).
